Azure Health Data Services を試してみる
最近、IT 業界暗いニュースが飛び交っています。
www.businessinsider.jp
www.businessinsider.jp
www.businessinsider.jp
www.businessinsider.jp
www.businessinsider.jp
いやはや、いつごろ景気が回復するのかなぁと思う今日この頃です。それはさておき、色々あって Azure Health Data Services を検証していくことになりました。Azure Health Data Services とは、FHIR に準拠したサービスとなっています。FHIR (Fast Healthcare Interoperability Resources)は、医療において、ヘルスケア情報を効率的かつ安全に交換するために開発されたデータ標準規格です。FHIRは、現在の業界標準であるHL7 v2やCDA(Clinical Document Architecture)などと比較して、より簡潔かつ革新的なフォーマットを採用しています。このことにより、患者のレコードをよりスムーズに移行したり、異なるヘルスケアシステム間での情報共有を容易にすることができます。※FHIR の説明は、少しだけ ChatGPT に頼ってみましたw
それでは、早速試してみましょう。今回は、Azure Health Data Services で FHIR サービスをデプロイし、Visual Studio Code を使って簡単に動作確認をしていきたいと思います。Azure Portal から、"Health Data Services ワークスペース" を選択します。
Azure Health Data Services ワークスペースは、Fast Healthcare Interoperability Resources (FHIR®) サービス、Digital Imaging and Communications in Medicine (DICOM®) サービス、MedTech サービスなど、すべての医療サービス インスタンスの論理コンテナーです。 ワークスペースでは、保護された正常性情報を移動できるコンプライアンス境界 (HIPAA、HITRUST) も作成されます。

- 現時点では、日本のリージョンは選択できません。※むぅ、医療データは国外保存ができないので、まだ日本では採用ができません(´;ω;`)

リソースグループ、ワークスペース名などを設定する
- FHIR サービスを追加します。

FHIR サービスを追加する
- FHIR サービスの設定し、作成します。

FHIR サービスを設定する
- FHIR サービスの CORS を設定し、"保存" します。

CORS を設定する
Azure Health Data Services の FHIR サービス (ここでは FHIR サービスと呼ばれます) では、 クロスオリジン リソース共有 (CORS) がサポートされています。 CORS を使用すると、あるドメイン (オリジン) のアプリケーションが異なるドメインのリソースにアクセスできる ("ドメイン間要求" と呼ばれます) ように、設定を構成することができます。
- Azure AD の "アプリの登録" → "新規登録" をします。

アプリの登録をする
- 名前を付けて、"登録"します。

アプリの登録をする
- クライアント ID、テナント ID はあとで使用するので、メモ帳などにコピーしておいてもよいかもしれません。

アプリを登録する
- "証明書とシークレット" → "新しいクライアントシークレット" をクリックします。

シークレットを設定する
- シークレットの設定し、"追加" をクリックします。

シークレットの設定をする
- シークレットの値をメモ帳などにコピーしておきます。※シークレットは厳重に管理しましょう。

シークレットをコピーする


- "委任されたアクセス許可" をクリックし、"user_impersonation" にチェックを入れ、"アクセス許可の追加" をクリックします。

API のアクセス許可をする
- FHIR サービスの設定をします。※FHIR メタデータエンドポイントもメモ帳などにコピーしておいてください。

FHIR サービスを設定する
- "アクセス制御 (IAM)" → "追加" → "ロールの割り当ての追加" をクリックします。

ロールの割り当てをする
- "FHIR データ共同作成者" を選択し、"次へ" をクリックします。

ロールの割り当てをする
- "メンバーを選択する" をクリックし、"myfhirapp" を選択します。

ロールの割り当てをする
- "レビューと割り当て" をクリックします。

ロールの割り当てをする
- これで準備ができましたので、Visual Studio Code から FHIR サービスに対してリクエストを投げてみます。VS Code の REST Client 拡張機能をインストールします。
- メモ帳にコピーしている各種情報を *.http ファイルに設定していきます。
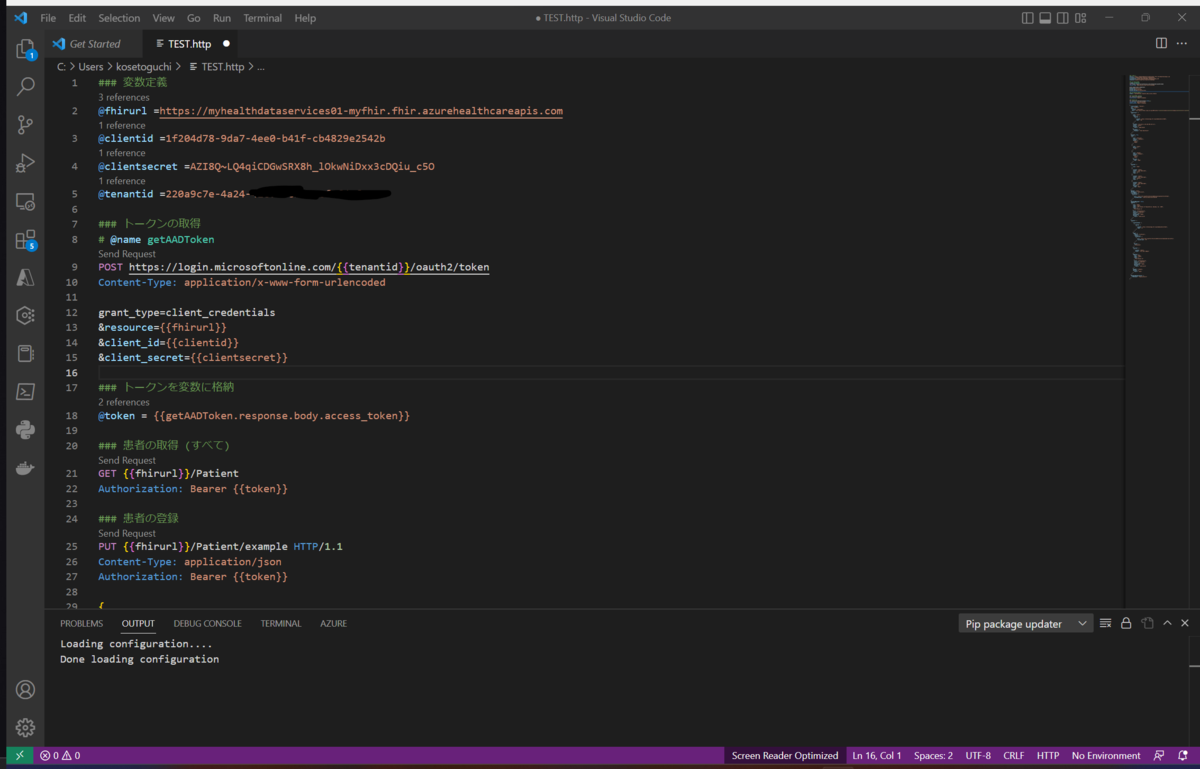
VS Code で REST Client を使用する
※実際に使用したコードは下記の通りです。
### 変数定義 環境に合わせて修正してください。 @fhirurl =https://myhealthdataservices01-myfhir.fhir.azurehealthcareapis.com @clientid =1f204d78-9da7-4ee0-b41f-cb4829e2542b @clientsecret =AZI8Q~LQ4qiCDGwSRX8h_lOkwNiDxx3cDQiu_c5O @tenantid =xxxxxxxxxx-xxxx-xxxxxxxx-xxxxx-xxxxxxxxxxxxx ### トークンの取得 # @name getAADToken POST https://login.microsoftonline.com/{{tenantid}}/oauth2/token Content-Type: application/x-www-form-urlencoded grant_type=client_credentials &resource={{fhirurl}} &client_id={{clientid}} &client_secret={{clientsecret}} ### トークンを変数に格納 @token = {{getAADToken.response.body.access_token}} ### 患者の取得 (すべて) GET {{fhirurl}}/Patient Authorization: Bearer {{token}} ### 患者の登録 PUT {{fhirurl}}/Patient/example HTTP/1.1 Content-Type: application/json Authorization: Bearer {{token}} { "resourceType": "Patient", "id": "example", "text": { "status": "generated", "div": "<div xmlns=\"http://www.w3.org/1999/xhtml\">\n\t\t\t<table>\n\t\t\t\t<tbody>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Name</td>\n\t\t\t\t\t\t<td>Peter James \n <b>Chalmers</b> ("Jim")\n </td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Address</td>\n\t\t\t\t\t\t<td>534 Erewhon, Pleasantville, Vic, 3999</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Contacts</td>\n\t\t\t\t\t\t<td>Home: unknown. Work: (03) 5555 6473</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>Id</td>\n\t\t\t\t\t\t<td>MRN: 12345 (Acme Healthcare)</td>\n\t\t\t\t\t</tr>\n\t\t\t\t</tbody>\n\t\t\t</table>\n\t\t</div>" }, "identifier": [ { "use": "usual", "type": { "coding": [ { "system": "http://terminology.hl7.org/CodeSystem/v2-0203", "code": "MR" } ] }, "system": "urn:oid:1.2.36.146.595.217.0.1", "value": "12345", "period": { "start": "2001-05-06" }, "assigner": { "display": "Acme Healthcare" } } ], "active": true, "name": [ { "use": "official", "family": "Chalmers", "given": [ "Peter", "James" ] }, { "use": "usual", "given": [ "Jim" ] }, { "use": "maiden", "family": "Windsor", "given": [ "Peter", "James" ], "period": { "end": "2002" } } ], "telecom": [ { "use": "home" }, { "system": "phone", "value": "(03) 5555 6473", "use": "work", "rank": 1 }, { "system": "phone", "value": "(03) 3410 5613", "use": "mobile", "rank": 2 }, { "system": "phone", "value": "(03) 5555 8834", "use": "old", "period": { "end": "2014" } } ], "gender": "male", "birthDate": "1974-12-25", "_birthDate": { "extension": [ { "url": "http://hl7.org/fhir/StructureDefinition/patient-birthTime", "valueDateTime": "1974-12-25T14:35:45-05:00" } ] }, "deceasedBoolean": false, "address": [ { "use": "home", "type": "both", "text": "534 Erewhon St PeasantVille, Rainbow, Vic 3999", "line": [ "534 Erewhon St" ], "city": "PleasantVille", "district": "Rainbow", "state": "Vic", "postalCode": "3999", "period": { "start": "1974-12-25" } } ], "contact": [ { "relationship": [ { "coding": [ { "system": "http://terminology.hl7.org/CodeSystem/v2-0131", "code": "N" } ] } ], "name": { "family": "du Marché", "_family": { "extension": [ { "url": "http://hl7.org/fhir/StructureDefinition/humanname-own-prefix", "valueString": "VV" } ] }, "given": [ "Bénédicte" ] }, "telecom": [ { "system": "phone", "value": "+33 (237) 998327" } ], "address": { "use": "home", "type": "both", "line": [ "534 Erewhon St" ], "city": "PleasantVille", "district": "Rainbow", "state": "Vic", "postalCode": "3999", "period": { "start": "1974-12-25" } }, "gender": "female", "period": { "start": "2012" } } ], "managingOrganization": { "reference": "Organization/1" } }
※患者情報のサンプルは、ここから取得しています。

- "### 患者の取得 (すべて)" というコメント下にある、"Send Request" をクリックすることで、FHIR サービスより患者情報を取得することができます。

患者情報を取得する
- "### 患者の登録" というコメント下にある、"Send Request" をクリックすることで、FHIR サービスに対して患者登録を依頼します。

患者情報を登録する
とりあえず試してみました。
最近、ロボット掃除機がほしくなってきた。Anker がほしいなぁ。
 【水拭き両用 / 自動ゴミ収集ステーション / 抗菌消臭ダストバッグ / 3200Pa 強力吸引 / AIマッピング 掃除経路確認 / アプリ操作 / 落下・衝突防止 / 静音設計 / 自動充電 / Alexa対応 / チャイルドロック / 最大24ヶ月保証】")
これも捨てがたい。
www.makuake.com
質問された内容を記事にしてみる - ケース1 - (Azure Migrate と Azure Lighthouse)
新年あけましておめでとうございます。旧年は大変お世話になりました。皆様のご健康とご多幸を心よりお祈り申し上げます。ここ数年、まともに記事を書いていませんでしたが、そろそろ技術的なことをまとめなければいけないと思い、記事を書こうと思った 2023/1/3 の午後です。今後とも "都内で働く SE の技術的なひとりごと" をご購読いただけると嬉しいです。自ら技術的なことを調査して記事化するということが苦手なため、今年から質問された内容を記事にしてみることにしました。(これが継続できるかはわかりませんが....)
さて、今回の質問内容は、
Azure Migrate で "検出と評価" を実施後に、検出と評価を行ったテナントとは別のテナントにレプリケーションをして移行ができないか?
というものでした。
お客さんのテナントをメンテナンスする場合には、お客さんのテナントにゲスト登録してもらって対応することが多いかと思います。ゲスト登録は面倒なので、嫌がる方も多いような気がします。そこで、Azure Lighthouse を使って、サブスクリプション or リソースグループを委任する方法をとるとこの辺りの面倒な管理から解放されます。Azure Lighthouse の概要は以下の URL を参照してください。
learn.microsoft.com
今回は下記のような構成で検証を行っています。

リソースグループ:rg-source には、仮想マシンをデプロイし、Nested Hyper-V を構成します。Hyper-V 上には、Windows Server 2012R2 と Windows Server 2016 がデプロイされています。Azure Migrate のアプライアンスもデプロイします。そして、それぞれの検出・評価・移行処理を進めていくことで、LogAnalytics, Key Vault, Recovery Service コンテナ, AADアプリ、ストレージアカウントのデプロイが実行されます。最終的には、リソースグループ:rg-target-azuremigrate-test に仮想マシンが移行されるといったものです。※AzureMigrateAppliance のサーバーは移行する必要はありません。今回は、少しでも多くのサーバーを移行してみたいと思い、アプライアンスのサーバーも移行対象にしてみました。
まず、Azure Lighthouse での委任方法です。まず、"検証の使用した構成" の図のテナント A 側の Azure Portal で下記の手順で ARM Template を作成します。
- マイカスタマーの概要ページから、"ARM テンプレートを作成" をクリックします。

マイカスタマーのページ - サブスクリプションを委任してもらうように設定します。設定後、"認証の追加" をクリックします。

ARM テンプレートの作成 - 今回は、グループに所属するユーザーに委任されたサブスクリプションを扱えるようにします。※今回は、Azure AD に AzureMigrateTest というグループにユーザーを数人追加しています。

認証の設定 - "テンプレートの表示" をクリックします。

テンプレートの表示 - "ダウンロード" をクリックします。template.json というファイルがダウンロードできます。

テンプレートのダウンロード
次に、"検証の使用した構成" の図のテナント B 側の Azure Portal で下記の手順でサブスクリプションを委任します。
- サービスプロバイダーで "サービスプロバイダーのオファー" をクリックし、"プランの追加" → "テンプレート経由で追加" をクリックします。

委任の処理 - テナント A で作成した template.json をアップロードします。

template.json のアップロード - 対象のサブスクリプションを選択し、"確認と作成" をクリックします。

サブスクリプションの選択 - "作成" をクリックします。

カスタムデプロイ - 委任されたことが確認できます。

委任結果 - テナント A 側で委任されたサブスクリプションが確認できます。

委任されたサブスクリプションの確認
これで、Azure Lighthouse の設定は完了です。Azure Migrate の検出・評価・移行については下記の URL を参照してください。
learn.microsoft.com
learn.microsoft.com
learn.microsoft.com
Azure Migrate のレプリケーションターゲットで、テナント B 側のサブスクリプション、リソースグループ、仮想ネットワークおよびサブネットを選択します。これで、テナント A 側で検出・評価を行ったものをテナント B 側にレプリケートおよび移行することが可能です。
Azure Lighthouse は複数環境管理に非常に便利ですよね。複数環境のログ管理なんかもできます。
learn.microsoft.com
Azure Sentinel と一緒に使用しても便利ですね。
learn.microsoft.com
もちろん、Policy も。
learn.microsoft.com
さらに、Arc も。
learn.microsoft.com
最近、スノーボード用にモンベル製品買ってみた。性能いいし、価格も安い。
webshop.montbell.jp
webshop.montbell.jp
webshop.montbell.jp
Azure Charts をためしてみた
最近、中々忙しくて記事が投稿できていません。アップデートも既に....
ryuchan.hatenablog.com
Azure Charts なるものを見つけたので、ちょっと触ってみます。
azurecharts.com
初期画面はこんな感じです。Solution をクリックします。

SLA をクリックすると、
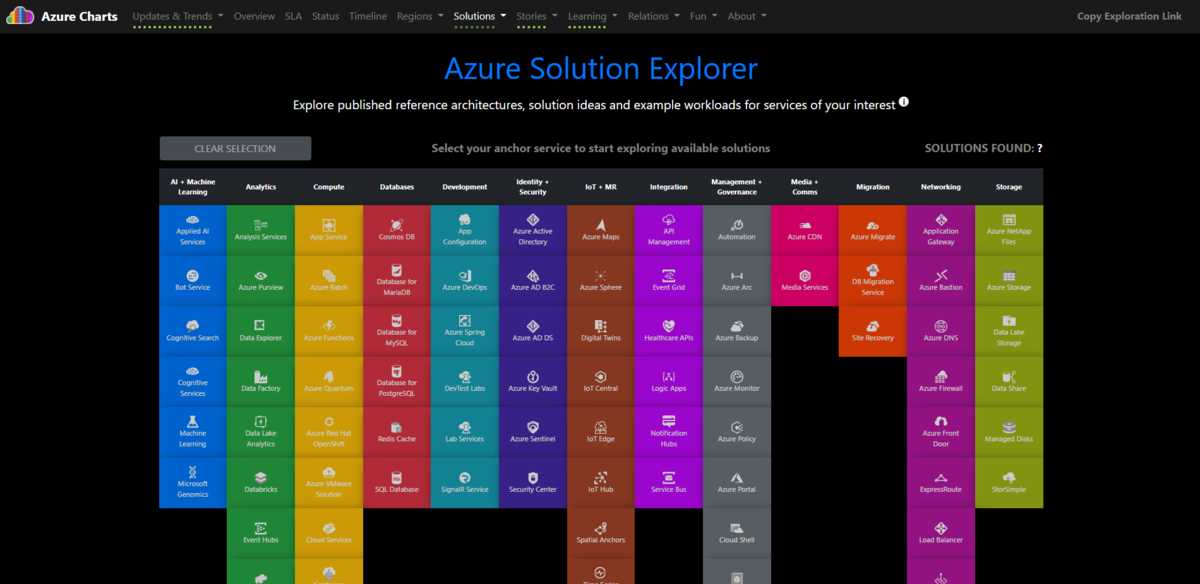
各 Azure サービスの SLA がグラフィカルに表示されます。


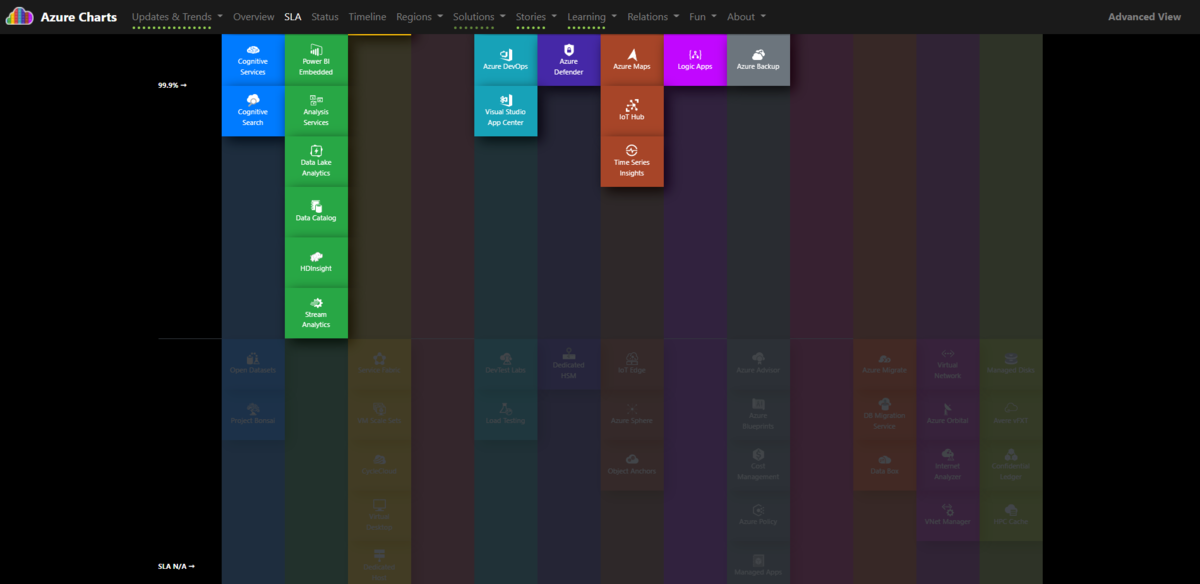
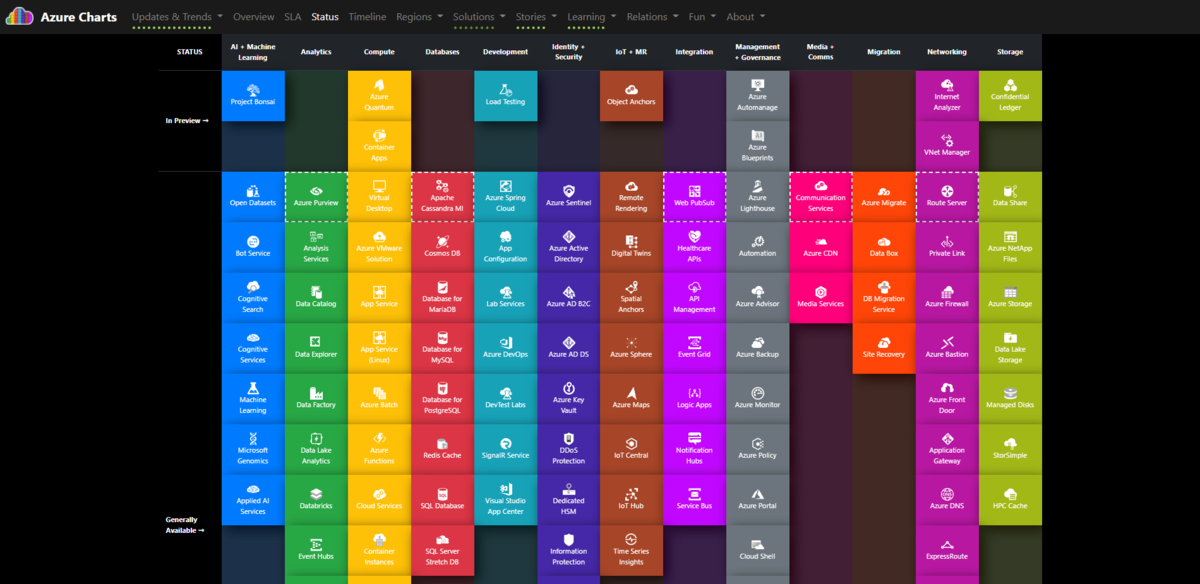
Status をクリックすると、

プレビュー、一般提供の状態がわかります。
Timeline をクリックすると、

どのリージョンにいつサービスが投入されるか確認できます。

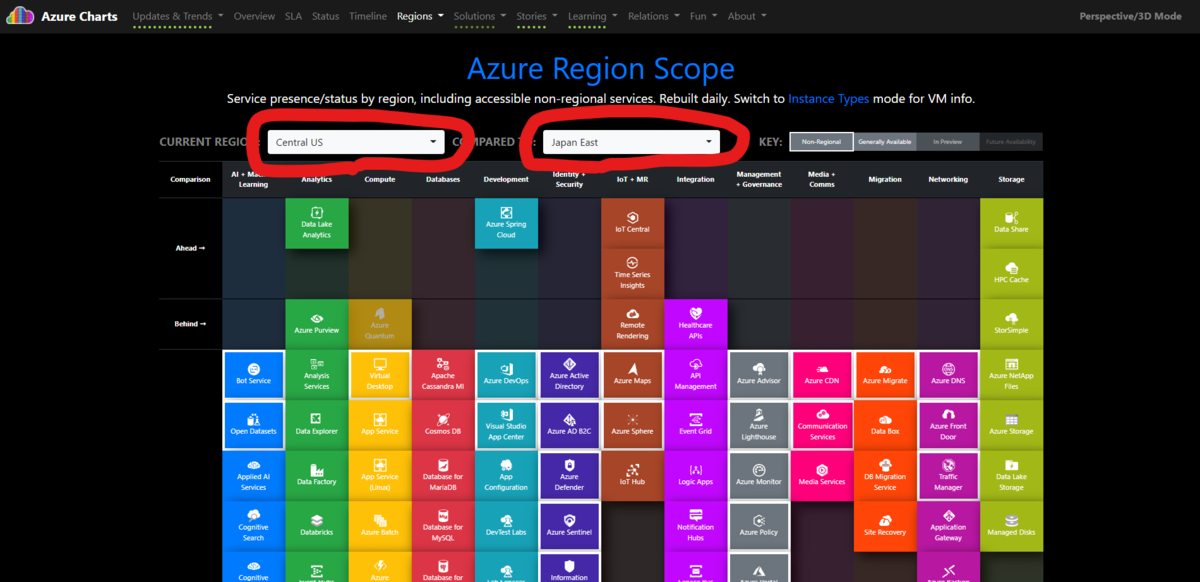
Region をクリックすると、

色々と機能はあるんですが、一つの機能としてリージョン間のサービスの有無などを確認することができます。
Solution をクリックすると、
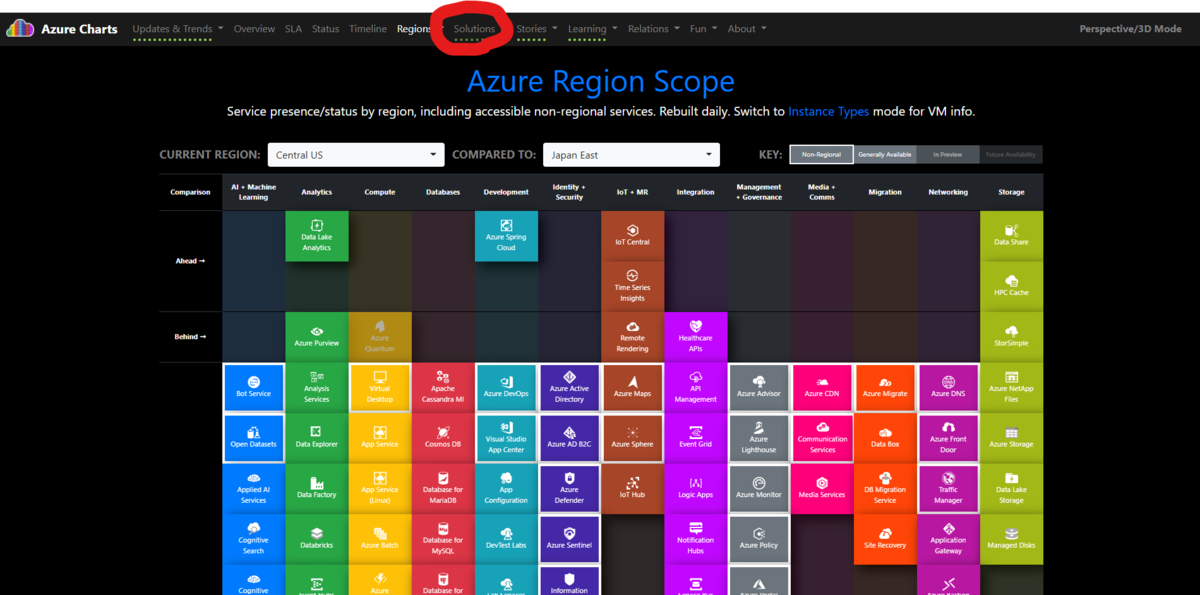
Azure のサービスが表示されます。
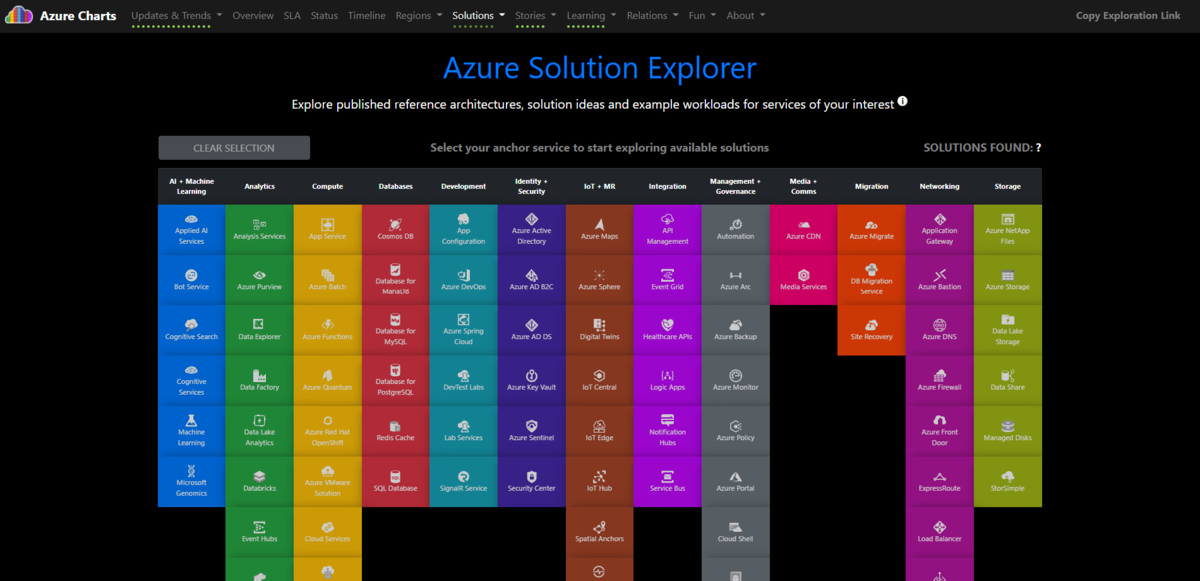
サービスをいくつか選択します。

上部のコンボボックスをクリックすると、

選択したサービスのアーキテクチャが表示されます。※これが一番お気に入り。
Stories は、導入事例、Learning は MS Learn、Relations はドキュメントなどへリンクされています。
いい感じに情報がまとめられていますね。素晴らしい!
Azure のアップデートをメモ代わりに興味あるところをザックリとまとめてみる (2022年1月分)
ここ最近、記事書くのを完全にサボっておりました。ボチボチ復活していこうかと思います。近頃、Azure Update が必要なことが多いので、メモ程度に纏めておこうかと思います。すべてのアップデートではないですが、ざっと箇条書き風に纏めていきます。
- New performance and logging capabilities in Azure Firewall
azure.microsoft.com
下記の二点の更新になります。- ファイアウォールのネットワーク ルール名のログ記録
元々、送信元、宛先 IP/ポート、およびアクション (許可または拒否) が表示されました。新しい機能では、ネットワーク ルールのイベント ログには、ポリシー名、ルールコレクショングループ、ルールコレクション、およびルール名ヒットも含まれるので、なんで拒否されているんだっけ?みたいなことがなくなりそう。 - ファイアウォール プレミアム のパフォーマンス向上
ファイアウォール "プレミアム" の最大スループットが 300 % (100 Gbps) 以上向上するようです。 - 上記の機能を試すには、機能フラグを ON にする必要があります。
https://docs.microsoft.com/ja-jp/azure/firewall/firewall-preview#feature-flags- ネットワーク ルール名のログ (プレビュー)
https://docs.microsoft.com/ja-jp/azure/firewall/firewall-preview#network-rule-name-logging-preview - Azure Firewall Premium パフォーマンス ブースト (プレビュー)
https://docs.microsoft.com/ja-jp/azure/firewall/firewall-preview#azure-firewall-premium-performance-boost-preview
- ネットワーク ルール名のログ (プレビュー)
- ファイアウォールのネットワーク ルール名のログ記録
- Azure NetApp Files features
azure.microsoft.com
三点アップデートがありました。- Azure NetApp Files のデュアルプロトコル ボリュームを作成する
https://docs.microsoft.com/ja-jp/azure/azure-netapp-files/create-volumes-dual-protocol - Azure NetApp Files 用に ADDS LDAP over TLS を構成する
https://docs.microsoft.com/ja-jp/azure/azure-netapp-files/configure-ldap-over-tls - SMB3 の暗号化を有効にする
https://docs.microsoft.com/ja-jp/azure/azure-netapp-files/azure-netapp-files-create-volumes-smb#smb3-encryption - あと、よくある質問 "Azure Files との機能比較"
https://docs.microsoft.com/ja-jp/azure/storage/files/storage-files-netapp-comparison - 個人的には、これが早く GA しないかなーと思ってます。
Azure NetApp Files Datastores for Azure VMware Solution is coming soon
https://azure.microsoft.com/en-us/updates/azure-netapp-files-datastores-for-azure-vmware-solution-is-coming-soon/
- Azure NetApp Files のデュアルプロトコル ボリュームを作成する
- Azure Site Recovery support for ZRS Managed Disks
azure.microsoft.com
ASR は、ZRS マネージドディスクをサポートするようになったようです。ZRS マネージドディスクを使用する仮想マシンを選択したセカンダリーリージョンにレプリケートし、保護することができます。プライマリリージョンが ZRS マネージディスクと判断すると、セカンダリリージョンに ZRS マネージディスクを作成するようです。可用性はかなり向上しそうですね。
- Azure Backup releases new updates for hybrid backups
azure.microsoft.com- Resource Guard を使用したマルチユーザー承認 (プレビュー)
https://docs.microsoft.com/ja-jp/azure/backup/multi-user-authorization
バックアップフローに承認という概念を組み込むことができるみたいですね。バックアップを保護するにはいい機能ですね。最近、ランサムウェアでバックアップまでやられたという病院もありました。
www.topics.or.jp
"バックアップ管理者がコンテナーに対して重要な操作を実行する場合は、Resource Guard へのアクセスを要求する必要があります。 バックアップ管理者は、セキュリティ管理者に連絡して、このような操作を実行するためのアクセス権の取得の詳細を確認できます。 これは、Azure Active Directory Privileged Identity Management (PIM) または組織が要求する他のプロセスを使用して行います。"
PIM だと P1 が必要になってしまうのか?
- Resource Guard を使用したマルチユーザー承認 (プレビュー)
- Support for private links available on the new agent
azure.microsoft.com
Azure Monitor Agent の Private Link を使えるようになりました。- Azure Monitor のデータ収集エンドポイント (プレビュー)
https://docs.microsoft.com/ja-jp/azure/azure-monitor/agents/data-collection-endpoint-overview - Azure Private Link を使用して、ネットワークを Azure Monitor に接続する
https://docs.microsoft.com/ja-jp/azure/azure-monitor/logs/private-link-security - Log Analytics から移行しましょう
https://docs.microsoft.com/ja-jp/azure/azure-monitor/agents/azure-monitor-agent-migration
- Azure Monitor のデータ収集エンドポイント (プレビュー)
- Multitasking in the cost analysis preview
azure.microsoft.com
リソースのコストを見る箇所で、タブで切り替えて参照できるようになったみたいです。
- Azure Key Vault increased service limits for all its customers
azure.microsoft.com
リージョンあたりのコンテナーごとに、10 秒間に許可される最大トランザクション数が 4000 に増加されました。あれ、日本語はアップデートされてない...英語は 4000 になってます。
- Azure Kubernetes updates
- FIPS enabled node pool in Azure Kubernetes
azure.microsoft.com
FIPS 140-2 が有効になっている Linux ベースのノード プールを作成できます。セキュリティを強化し、FedRAMP 準拠の一部としてセキュリティを満たすことができるようです。(日本では関係ないですね。) - Ultra disks support on AKS
azure.microsoft.com
Ultra Disk がサポートされました。 - Containerd support for Windows in AKS
azure.microsoft.com
Windows サーバー コンテナーのコンテナー化をサポートするようになりました。これは、Kubernetes バージョン 1.20 以降で使用できます。 - Azure Kubernetes support for upgrade events
azure.microsoft.com
新しいイベントにより、Azure ポータルまたは CLI を使用してアップグレードの状態をより簡単に表示できます。 - Kubernetes version alias support in AKS
azure.microsoft.com
パッチ番号を指定する必要がないようにセットアップを簡略化しています。たとえば、Kubernetes 1.20.1 の代わりに Kubernetes 1.20 を指定できます。正確なパッチ番号を指定しないことで、選択したマイナー バージョンの最も高いパッチ バージョンに自動的に配置されます。
- FIPS enabled node pool in Azure Kubernetes
- Managed Certificate support for Azure API Management
azure.microsoft.com
Azure API Management のマネージド証明書がサポートが、パブリック プレビューになりました。これにより、Azure API Management によってプロビジョニング、管理、自動更新された証明書を使用できます。
- Azure SQL—General availability updates for late January 2022
azure.microsoft.com- バックアップ ストレージの冗長性を構成する
https://docs.microsoft.com/ja-jp/azure/azure-sql/database/automated-backups-overview?tabs=managed-instance#configure-backup-storage-redundancy
既定値は geo 冗長です。 ローカル冗長、ゾーン冗長が選択できるようになった?データベース関連いまいち追えていないので、自信なしです。
- バックアップ ストレージの冗長性を構成する
- Support for managed identity in Azure Cache for Redis
azure.microsoft.com
Redis 用 Azure Cache では、マネージド ID を使用したストレージ アカウント接続の認証がサポートされるようになったようです。IAM で設定するだけになるので、セキュリティも向上しますね。
https://docs.microsoft.com/ja-jp/azure/active-directory/managed-identities-azure-resources/overview#managed-identity-types
- Azure Monitor
- Azure Monitor log alerts new version
azure.microsoft.com - A new and improved alert rule creation experience
azure.microsoft.com
ウィザード形式で設定できるようになりました。ずっと、プレビューポータルで使用していたため、一瞬何が変わったの?と混乱してしまいました笑
- Azure Monitor log alerts new version
- Create multiple data export rules to the same event hub namespace
azure.microsoft.com
LogAnalytics からのデータエクスポートで複数の EventHub に対して、異なるログを送れる感じですかね。- イベント ハブ
https://docs.microsoft.com/ja-jp/azure/azure-monitor/logs/logs-data-export?tabs=portal#event-hub - Azure Monitor の Log Analytics ワークスペースのデータ エクスポート (プレビュー)
https://docs.microsoft.com/ja-jp/azure/azure-monitor/logs/logs-data-export?tabs=portal
早くリリースされるといいですね。
- イベント ハブ
- Azure Static Web Apps enterprise-grade edge
azure.microsoft.com
下記の機能が追加されます。
- Announcing price reductions for Azure confidential computing
azure.microsoft.com
機密性の高い仮想マシンが33%ほど安くなるようです。
azure.microsoft.com
- Load Balancer SKU upgrade through PowerShell script
azure.microsoft.com
PowerShell スクリプトを使用して、Azure ロード バランサーを Basic SKU から Standard SKU にアップグレードできるようになりました。
- Multiple custom BGP APIPA addresses for active VPN gateways
azure.microsoft.com
アクティブ/アクティブ VPN ゲートウェイのすべての SKU が、各インスタンスに対して複数のカスタム BGP APIPA アドレスをサポートするようになりました。自動プライベート IP アドレス指定 (APIPA) アドレスは、VPN 接続の BGP IP アドレスとして一般的に使用されます。
- Azure Site Recovery での Azure Policy のサポート
azure.microsoft.com
特定のサブスクリプションまたはリソース グループに対してディザスター リカバリー ポリシーを作成すると、そのサブスクリプションまたはリソース グループに追加されるすべての新しい VM に対して、自動的に Azure Site Recovery が有効になります。
- Azure Backup - オートメーションの更新 - 2021 年
azure.microsoft.com- Recovery Services CLI の一般提供開始: Azure Backup の CLI コマンドが最新の CLI 標準を使用するように更新され、その一般提供が開始されました。大きな変更は行われておらず、お客様はパブリック プレビュー期間中と同様の方法で、コマンドを使用することができます。また、パラメーター セットの拡張機能 (たとえば、コマンドで ARM ID を直接使用する機能) を利用して、スクリプトの作成エクスペリエンスを簡素化することもできます。
- バックアップ コンテナー ワークロードの PS/CLI サポート: Azure Backup に、バックアップ コンテナーでサポートされているワークロード (PostgreSQL Server の Azure Databases、Azure BLOB、Azure Disk など) に対応した PowerShell と CLI のサポートが含まれるようになりました。
- バックアップ コンテナー ワークロードに対する Terraform のサポートPostgreSQL DB バックアップ、BLOB バックアップ、Disk バックアップ用の Terraform モジュールが公開されました。
- Azure Backup 用の Bicep テンプレート: Bicep は、宣言型の構文を使用して Azure リソースをデプロイするドメイン固有言語 (DSL) です。簡潔な構文、信頼性の高いタイプ セーフ、およびコードの再利用のサポートが提供されます。Azure Backup ユーザーが Bicep のメリットを利用できるように、Azure VM バックアップ、BLOB バックアップ、Disk バックアップ用の Bicep サンプル テンプレートが公開されました。
- PS/CLI での新機能のサポート: アーカイブ ストレージ、CMK のユーザー割り当て ID、マネージド ディスク復元用の MSI 認証など、この期間に一般提供が開始された新機能のほとんどに対し、PS/CLI サポートが追加されました。
- Bicep テンプレートはいいですね。
- Azure Traffic Manager: Additional IP addresses for endpoint monitoring service
azure.microsoft.com
Traffic Manager のエンドポイント監視サービス内に展開されるプローブの数を増加させるようです。正常性プローブの数が増加します。サービスタグ (AzureTrafficManager) を使っていなければ、下記の URL から更新された IP をチェックする必要があります。
https://docs.microsoft.com/en-us/azure/virtual-network/service-tags-overview#discover-service-tags-by-using-downloadable-json-files
- Azure SQL—Public preview updates for early January 2022
https://azure.microsoft.com/ja-jp/updates/azure-sql-public-preview-updates-for-early-january-2022/- Auto-failover groups for Azure SQL Hyperscale now in preview
techcommunity.microsoft.com
アクティブ geo レプリケーショングループと自動フェールオーバー グループを使用する Azure SQL Hyperscale データベースの強制フェールオーバーおよび計画フェールオーバーがサポートされるようです。
- Auto-failover groups for Azure SQL Hyperscale now in preview
- Microsoft Defender for Cloud updates for December 2021
azure.microsoft.com- 一般公開 (GA) 向け Microsoft Defender for Containers プランのリリース
https://docs.microsoft.com/ja-jp/azure/defender-for-cloud/release-notes#microsoft-defender-for-containers-plan-released-for-general-availability-ga
2 年以上前に、Microsoft Defender for Cloud 内の Azure Defender サービスの一環として、Defender for Kubernetes とコンテナー レジストリ用 Defender が導入されました。Microsoft Defender for Containers のリリースに伴い、これらの 2 つの既存の Defender プランを統合しました。 - 一般公開 (GA) 向け Microsoft Defender for Storage の新しいアラートのリリース
https://docs.microsoft.com/ja-jp/azure/defender-for-cloud/release-notes#new-alerts-for-microsoft-defender-for-storage-released-for-general-availability-ga
Microsoft Defender for Storage はこれらのスキャナーを検出するため、それらをブロックし、状態を修復できます。これを検出していた以前のアラートは、"パブリック ストレージ コンテナー の匿名スキャン" と呼ばれていました。 検出された疑わしいイベントをより明確化するために、これを 2 つの新しいアラートに分けました。 これらのアラートは、Azure Blob Storage にのみ関連します。- Publicly accessible storage containers successfully discovered (パブリックにアクセス可能なストレージ コンテナーの検出に成功しました)(Storage.Blob_OpenContainersScanning.SuccessfulDiscovery)
- Publicly accessible storage containers successfully discovered (パブリックにアクセス可能なストレージ コンテナーのスキャンに失敗しました)(Storage.Blob_OpenContainersScanning.FailedAttempt)
- Microsoft Defender for Storage のアラートの改善
https://docs.microsoft.com/ja-jp/azure/defender-for-cloud/release-notes#improvements-to-alerts-for-microsoft-defender-for-storage
初期のアクセス アラートの精度が向上し、調査をサポートするデータが多く追加されました。脅威アクターは、初期アクセスでさまざまな手法を用いて、ネットワーク内の足がかりを得ようとします。 この段階で動作の異常を検出する Microsoft Defender for Storage の 2 つのアラートは、検知ロジックが改善され、調査をサポートするデータが追加されました。 - ネットワーク層アラートからの 'PortSweeping' アラートの削除
https://docs.microsoft.com/ja-jp/azure/defender-for-cloud/release-notes#portsweeping-alert-removed-from-network-layer-alerts
"Possible outgoing port scanning activity detected (送信ポートのスキャン アクティビティの可能性が検出されました)(PortSweeping)" は、ネットワーク層アラートから削除されました。
- 一般公開 (GA) 向け Microsoft Defender for Containers プランのリリース
アップデートではないですが、下記の記事も気になります。Azure DDoS Protection 優秀な結果を残してますね。
azure.microsoft.com
Microsoft は 1 件の 3.47 Tbps の攻撃を軽減、さらに 2.5 Tbps を超える攻撃も 2 件
昨年 10 月、Microsoft は、Azure に 2.4 テラビット/秒 (Tbps) の DDoS 攻撃があり、Microsoft がその軽減に成功したことを報告しました。その後、Microsoft はより大規模な攻撃を 3 件軽減しています。11 月に、Microsoft は、3.47 Tbps のスループットと、アジアでの Azure のお客様を対象としたパケット レート 3 億 4,000 万パケット/秒 (pps) の DDoS 攻撃を軽減しています。これは、史上最大の攻撃であったと考えています。
Azure Update は一カ月に一回だと、手抜きになるし、またすぐ記事書かなくなりそうなので、週一にしようかな。あ、2/1 から 2/6 の分をもう記事にしないと!(サボる気がするw)
また、スキー場いくので、そろそろレンタルやめてちゃんと道具買おうかな。けど、最近あんまりいかないから、ウェア、グローブとゴーグルだけでもいい気がする。
 MENS MOUNTAIN PULLOVER 20389102001 TRUE BLACK M")
 スノーボード ウェア メンズ パンツ MEN'S COVERT PANT 2019-20年モデル Lサイズ TRUE BLACK 13139105001")
 スノーボード 板 メンズ 20-21 DEEP THINKER CAMBER 172001 04000 (154/Men's)")


![DRAGON ゴーグル スペアレンズ ドラゴン スノーボード PXV2 ピーエックスブイツー [1L62~1L66] JAPAN LUMALENS スノー ゴーグル SNOW SPARE LENS (LL_J.SILVER_ION)](https://m.media-amazon.com/images/I/31pqP2jESeL._SL500_.jpg "DRAGON ゴーグル スペアレンズ ドラゴン スノーボード PXV2 ピーエックスブイツー [1L62~1L66] JAPAN LUMALENS スノー ゴーグル SNOW SPARE LENS (LL_J.SILVER_ION)")
 スノーボードグローブ メンズ ミット ミトン MEN'S PROFILE UNDER MITT 2019-20年モデル Lサイズ TRUE BLACK 10386100002")
Summary of SQL Server tuning - Part 3 - (How much performance does it improve?)
Also today, I am translating the old Japanese post to English while watching "HAKONE EKIDEN". Which does get first prize, Soka-Univ. or Komazawa-Univ? I am looking forward to know the result. In this time, I try to translate following post.
ryuchan.hatenablog.com
I've been slacking a bit on writing my blog lately. I'd like to resume it again. This is a supplement to post on “
Summary of SQL Server Tuning - Part 1 - (Examine indexes) - 都内で働くSEの技術的なひとりごと / Technical soliloquy of System Engineer working in Tokyo
"
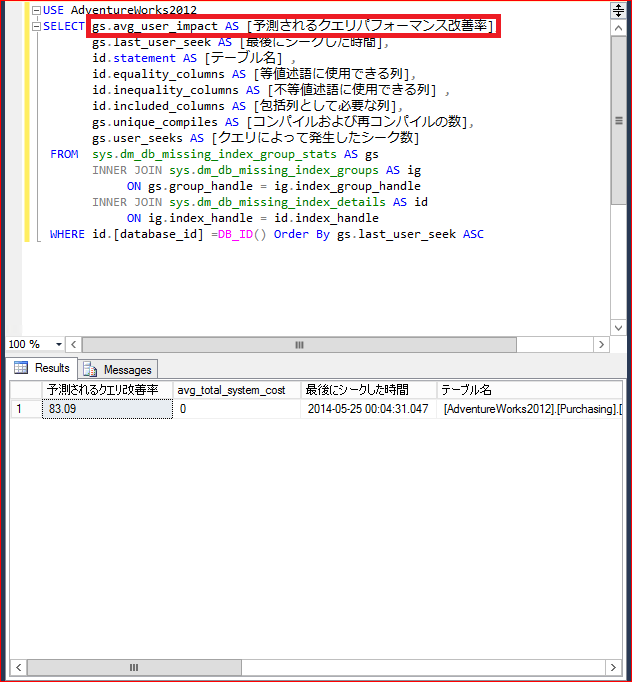
Let's start with a quick way to see how many indexes are missing for a query that executing the against database. Let's issue the following query in SQL Server Management Studio (just a simple count...).
SELECT DB_NAME(database_id) as [Database name], count(*) as [Number of expected indexes that do not exist] FROM sys.dm_db_missing_index_details GROUP BY DB_NAME(database_id)

Depending on the number of outputs, a sad reality awaits. Because the indexes have not been created, it is possible to grasp the current situation where the DBMS is under a tremendous load. It is difficult to know what to do with just this, so I add “avg_user_impact” to query that used on “Summary of SQL Server Tuning - Part 1 - (Examine indexes) - 都内で働くSEの技術的なひとりごと / Technical soliloquy of System Engineer working in Tokyo". This is the percentage improvement in performance when an index is created.
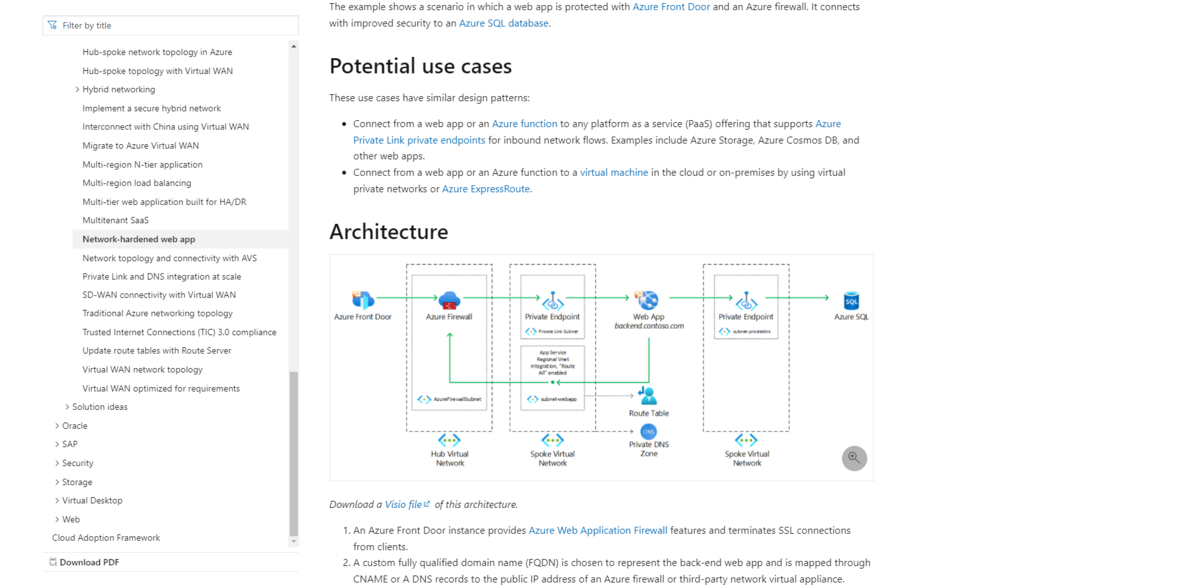
USE AdventureWorks2012 SELECT gs.avg_user_impact AS [Predicted query performance improvement rate], gs.last_user_seek AS [Time of last seek], id.statement AS [Table name] , id.equality_columns AS [Column that can be used for equality predicates], id.inequality_columns AS [Column that can be used for inequality predicates] , id.included_columns AS [Column required as included columns], gs.unique_compiles AS [Number of compilations and recompilations], gs.user_seeks AS [The number of seeks generated by the query] FROM sys.dm_db_missing_index_group_stats AS gs INNER JOIN sys.dm_db_missing_index_groups AS ig ON gs.group_handle = ig.index_group_handle INNER JOIN sys.dm_db_missing_index_details AS id ON ig.index_handle = id.index_handle WHERE id.[database_id] =DB_ID() Order By gs.last_user_seek ASC
The result was an improvement of 83.09%. I think we need to create indexes, but it is necessary to think about it carefully because it can cause performance degradation and capacity increase when updating tables (Be especially careful with the included column....). By adding this column, I think it will be an indicator of which indexes should be prioritized. Good luck and improve your query performance (If I had properly added this in my previous post, I wouldn't have needed to add it....).
Ginger is a really useful website to check my grammar!!
www.getginger.jp
Summary of SQL Server Tuning - Part 2 - (Filtered Index)
Happy New Year to all! I am translating the old Japanese post while watching "Hakone Ekiden". This year, Tokai Univ. team is quite strong. Next, I try to translate following post.
ryuchan.hatenablog.com
Today, I suddenly realized that the "SQL Server Tuning" series ended with "Part 1” lol. So I thought it would be a good idea to end with Part 1, so I'd like to put together Part 2 (Too random ….). In this post, I explain about "filtered index". This feature added in SQL Server 2008.
A filtered index, for example, if the contents of one field of a table are mostly NULL, can create an index that contains only records where the value of that field is not NULL (The filter condition is like what you would specify in a Where clause.).
Let's try with the usual “AdventureWorks" database. The target table is “Sales.SalesOrderDetail".

Create an index on the “CarrierTrackingNumber" column.

The number of rows in the Leaf level is "121317", which matches the total number of rows.

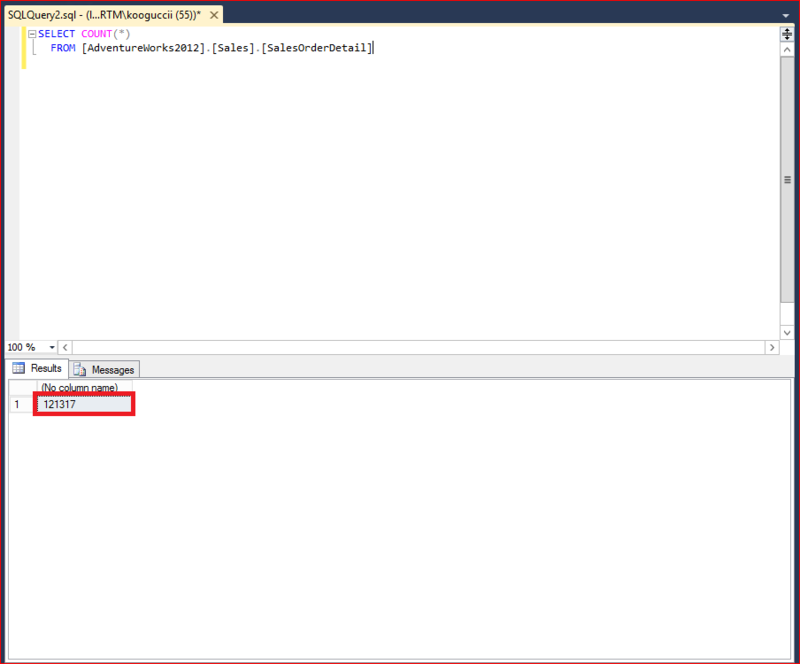
Similarly, create an index on the “CarrierTrackingNumber" column. However, in this time, set the filter condition to "CarrierTrackingNumber IS NOT NULL".
The number of rows in the Leaf level is "60919", which is the same as the number of rows excluding the null records.
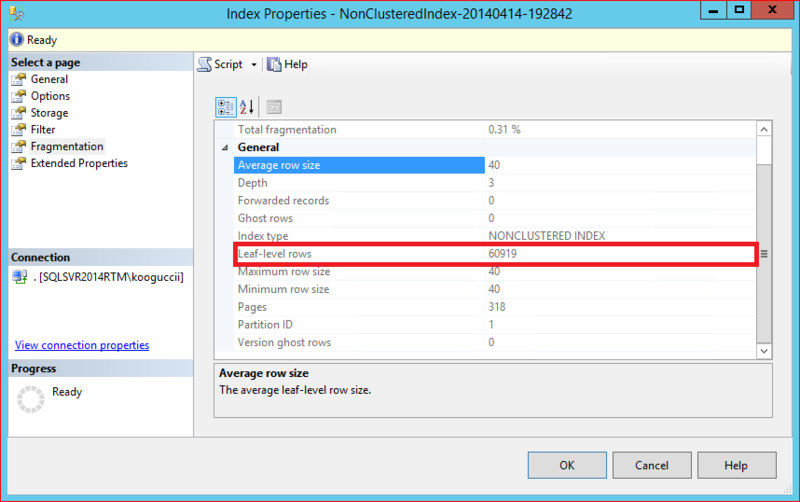

By using "filtered index", you can perform an efficient search that matches certain conditions. Also, since the number of physical rows stored in the index will be reduced, the I / O load will be reduced, and the speed will be improved.
However, it is quite difficult to design an index that takes the business perspective and it requires a lot of its experience.
Ginger is a really useful website to check my grammar!!
www.getginger.jp