Happy New Year to all! I am translating the old Japanese post while watching "Hakone Ekiden". This year, Tokai Univ. team is quite strong. Next, I try to translate following post.
ryuchan.hatenablog.com
Today, I suddenly realized that the "SQL Server Tuning" series ended with "Part 1” lol. So I thought it would be a good idea to end with Part 1, so I'd like to put together Part 2 (Too random ….). In this post, I explain about "filtered index". This feature added in SQL Server 2008.
A filtered index, for example, if the contents of one field of a table are mostly NULL, can create an index that contains only records where the value of that field is not NULL (The filter condition is like what you would specify in a Where clause.).
Let's try with the usual “AdventureWorks" database. The target table is “Sales.SalesOrderDetail".

Create an index on the “CarrierTrackingNumber" column.

The number of rows in the Leaf level is "121317", which matches the total number of rows.

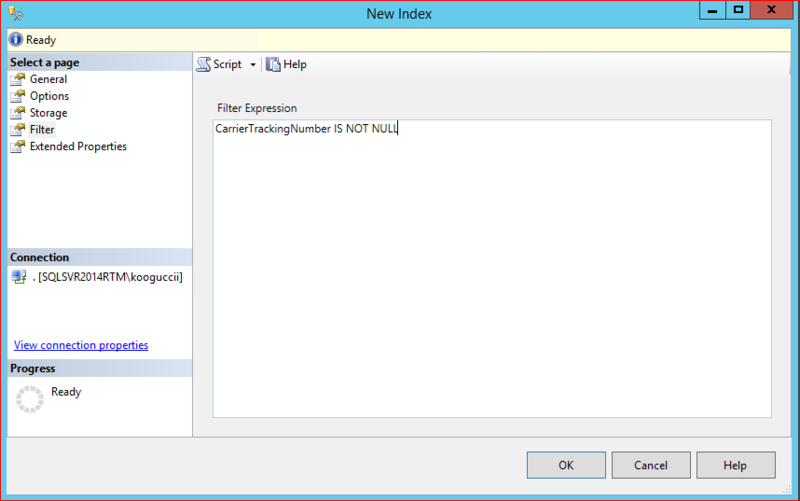
Similarly, create an index on the “CarrierTrackingNumber" column. However, in this time, set the filter condition to "CarrierTrackingNumber IS NOT NULL".
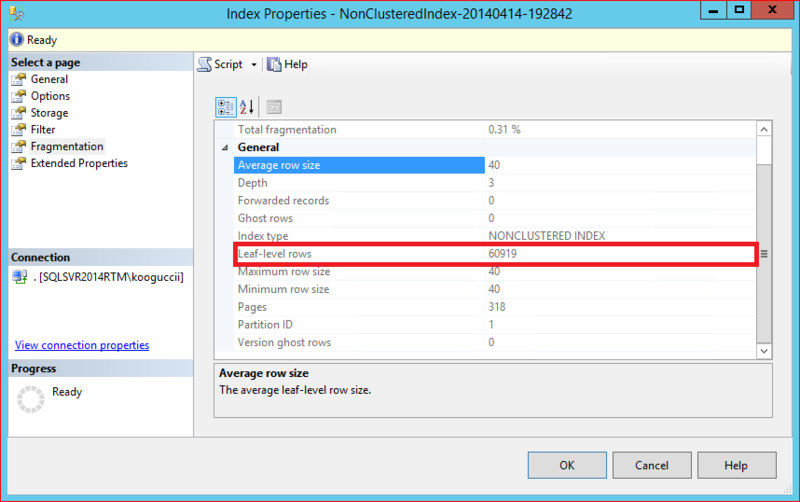
The number of rows in the Leaf level is "60919", which is the same as the number of rows excluding the null records.

By using "filtered index", you can perform an efficient search that matches certain conditions. Also, since the number of physical rows stored in the index will be reduced, the I / O load will be reduced, and the speed will be improved.
However, it is quite difficult to design an index that takes the business perspective and it requires a lot of its experience.
Ginger is a really useful website to check my grammar!!
www.getginger.jp