Summary of SQL Server tuning - Part 3 - (How much performance does it improve?)
Also today, I am translating the old Japanese post to English while watching "HAKONE EKIDEN". Which does get first prize, Soka-Univ. or Komazawa-Univ? I am looking forward to know the result. In this time, I try to translate following post.
ryuchan.hatenablog.com
I've been slacking a bit on writing my blog lately. I'd like to resume it again. This is a supplement to post on “
Summary of SQL Server Tuning - Part 1 - (Examine indexes) - 都内で働くSEの技術的なひとりごと / Technical soliloquy of System Engineer working in Tokyo
"
Let's start with a quick way to see how many indexes are missing for a query that executing the against database. Let's issue the following query in SQL Server Management Studio (just a simple count...).
SELECT DB_NAME(database_id) as [Database name], count(*) as [Number of expected indexes that do not exist] FROM sys.dm_db_missing_index_details GROUP BY DB_NAME(database_id)

Depending on the number of outputs, a sad reality awaits. Because the indexes have not been created, it is possible to grasp the current situation where the DBMS is under a tremendous load. It is difficult to know what to do with just this, so I add “avg_user_impact” to query that used on “Summary of SQL Server Tuning - Part 1 - (Examine indexes) - 都内で働くSEの技術的なひとりごと / Technical soliloquy of System Engineer working in Tokyo". This is the percentage improvement in performance when an index is created.
USE AdventureWorks2012 SELECT gs.avg_user_impact AS [Predicted query performance improvement rate], gs.last_user_seek AS [Time of last seek], id.statement AS [Table name] , id.equality_columns AS [Column that can be used for equality predicates], id.inequality_columns AS [Column that can be used for inequality predicates] , id.included_columns AS [Column required as included columns], gs.unique_compiles AS [Number of compilations and recompilations], gs.user_seeks AS [The number of seeks generated by the query] FROM sys.dm_db_missing_index_group_stats AS gs INNER JOIN sys.dm_db_missing_index_groups AS ig ON gs.group_handle = ig.index_group_handle INNER JOIN sys.dm_db_missing_index_details AS id ON ig.index_handle = id.index_handle WHERE id.[database_id] =DB_ID() Order By gs.last_user_seek ASC
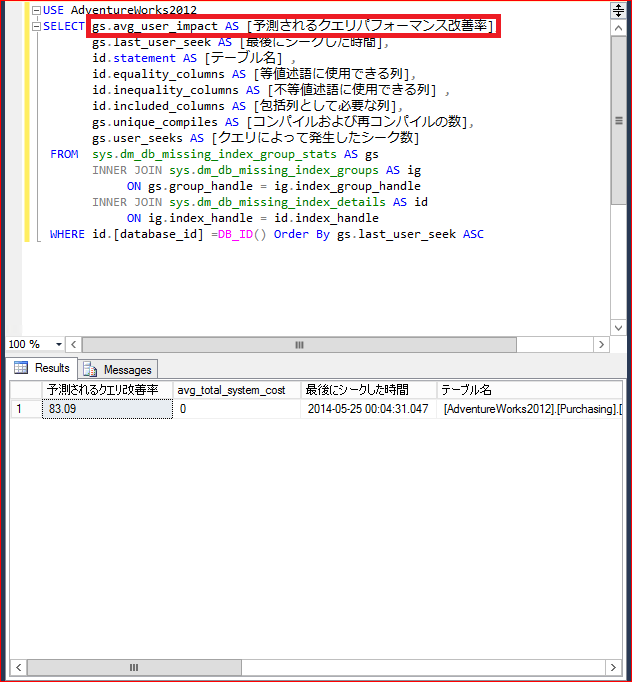
The result was an improvement of 83.09%. I think we need to create indexes, but it is necessary to think about it carefully because it can cause performance degradation and capacity increase when updating tables (Be especially careful with the included column....). By adding this column, I think it will be an indicator of which indexes should be prioritized. Good luck and improve your query performance (If I had properly added this in my previous post, I wouldn't have needed to add it....).
Ginger is a really useful website to check my grammar!!
www.getginger.jp